嘛,学校上线了新的教务系统和选课系统,然后之前的刷课之类的脚本就要重写辣。之前的版本是学长用Java写的一个模拟登陆之类的脚本,然而作为两年都没用Java写过工程类代码的我来说,“人生苦短,我用Python”,于是便花了四个小时写了个新的脚本,具体的方式在这里记录一下,供自己以后回顾以及萌萌哒学弟学妹们参考。
首先,我也是第一次写这种带些“黑科技”性质的脚本,如果有不完善的地方欢迎大家提出问题,进行讨论。大体的思路是:设定一个间隔时间,不断地查询某个课程的剩余容量,发现有课余量的时候便开始选课。
因此,脚本需要实现的主要有三个模块:模拟登陆模块、查询课余量模块、选课模块,下面分别对三个模块进行说明:
模拟登陆
我们先来看一下登录界面  啊,大概长这样,在cmd里ping一下域名找到IP
啊,大概长这样,在cmd里ping一下域名找到IP  然后打开Wireshark,对IP地址添加filter,过滤掉其他信息
然后打开Wireshark,对IP地址添加filter,过滤掉其他信息  刷新网页,登录,则记录了通信过程的数据包(121开头的IP为本机,202为网站的IP)
刷新网页,登录,则记录了通信过程的数据包(121开头的IP为本机,202为网站的IP)
 很明显带着login的那个东西传送的是登录信息,打开看看:
果然,直接POST了一个类型为application/x-www-form-urlencoded的数据给了子目录/b/ajaxLogin,数据内容为
很明显带着login的那个东西传送的是登录信息,打开看看:
果然,直接POST了一个类型为application/x-www-form-urlencoded的数据给了子目录/b/ajaxLogin,数据内容为
1
2"j_username" = "学号"
"j_password" = "密码"1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33def login(username,password):
urlLogin='http://bkjwxk.sdu.edu.cn/b/ajaxLogin'
data = {
"j_username": username,
"j_password": password,
}
data = urllib.parse.urlencode(data).encode('utf-8') #注意编码
try:
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Accept': '*/*',
'Origin': 'http://bkjwxk.sdu.edu.cn',
'Connection': 'keep-alive',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Accept-Encoding':' gzip, deflate',
'Host': 'bkjwxk.sdu.edu.cn'
}
request = urllib.request.Request(url=urlLogin, headers=headers, data=data)
cookie = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie))
r = opener.open(request)
response = r.read().decode('utf-8') #注意解码
print(response)
if(response!='"success"'):
print("登陆失败")
sys.exit()
print("登陆成功")
return cookie;
except Exception as e:
print("Login Error: %s"%e)
几点需要注意的地方:
- header中的Content-Type最为重要,它规定了数据发送的形式。而header的其他内容加不加好像都可以得到正确的结果
- 注意cookie的获取和保存,这里使用了http.cookiejar.CookieJar
之后,如果登陆成功会返回"success",不成功则返回了提示信息,我们可以通过打印response来看到。 登陆成功的话,就能返回cookie进行下一步对课程剩余量的爬虫了。
爬取剩余课程容量
如同刚才的做法,先在网页中模拟对课余量的查询,然后抓包分析数据包内容,这里不再详述,直接看发送和接受的数据包的结果:
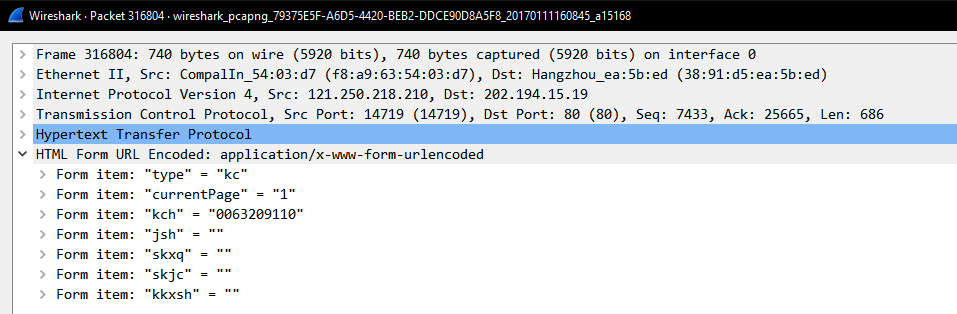
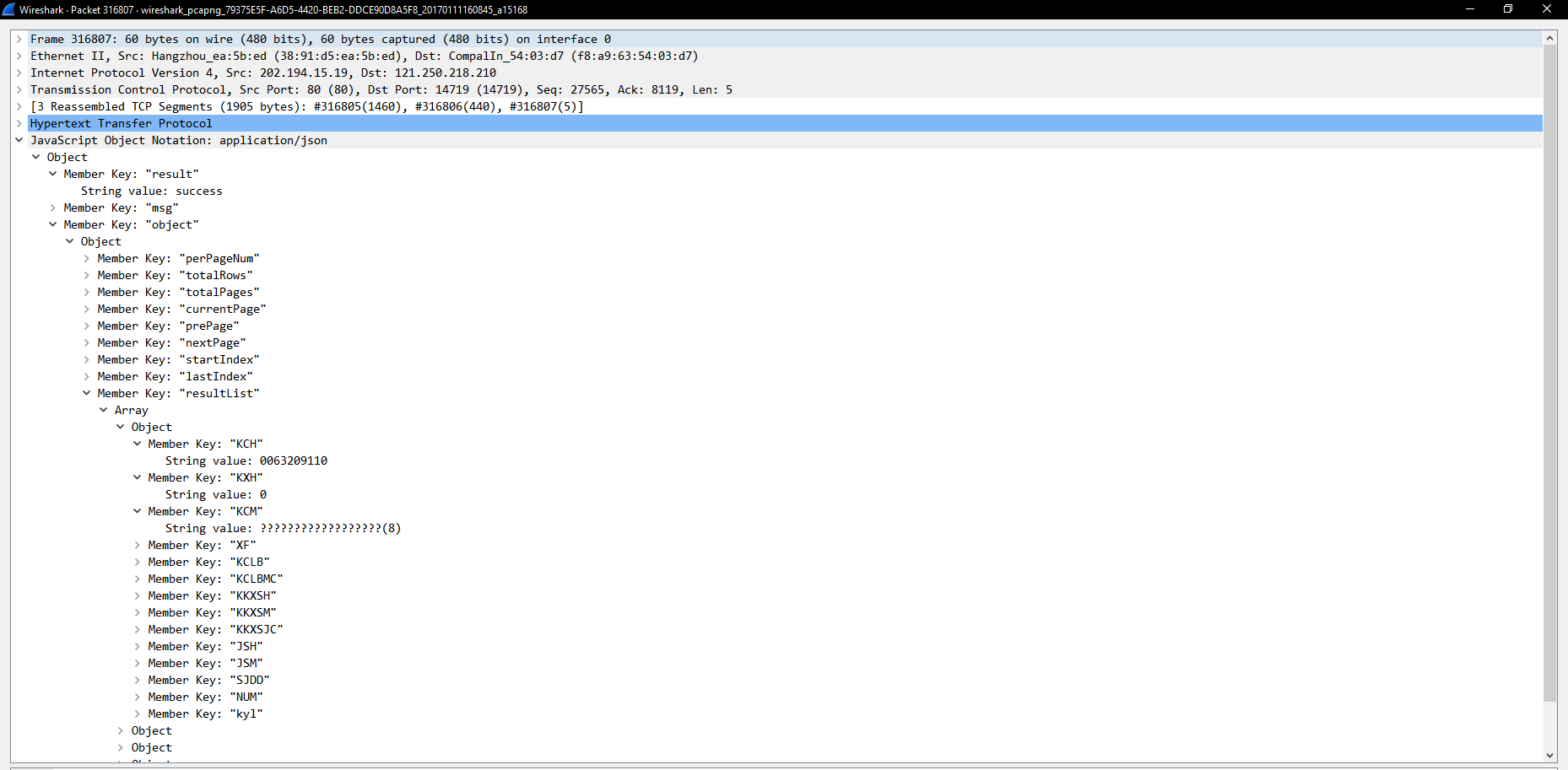 厉害了,发送格式是application/x-www-form-urlencoded,返回直接返回了json,这样分析就方便多了,具体数据代表的含义的话简单地说一下,具体还是自己抓了包看吧:
发送信息:
厉害了,发送格式是application/x-www-form-urlencoded,返回直接返回了json,这样分析就方便多了,具体数据代表的含义的话简单地说一下,具体还是自己抓了包看吧:
发送信息: 1
2Form item: "currentPage" = "1" #当前页号
Form item: "kch" = "0063209110" #课程号1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18JavaScript Object Notation: application/json
Object
Member Key: "result" #成功与否
String value: success
Member Key: "msg" #不成功的话提示信息
Null value
Member Key: "object" #返回数据
Object
Member Key: "perPageNum" #每一页的课程数量
Member Key: "totalRows"
Member Key: "totalPages" #一共多少页
Member Key: "currentPage" #当前页
Member Key: "prePage" #前一页
Member Key: "nextPage" #后一页
Member Key: "startIndex" #本页开始的Index
Member Key: "lastIndex" #本页结束的Index
Member Key: "resultList" #结果数组
Array1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54def checkLeft(kch,kxh,cookie):
try:
urlCheck=urlbase+'/b/xk/xs/kcsearch'
curPage = 1
totPage = 100
find = False
while(curPage <= totPage and not find):
# print("curPage %d"%curPage)
# print("totPage %d"%totPage)
# print("kch %s"%kch)
data = {
"type": "kc",
"currentPage": curPage,
"kch": kch,
"jsh": "",
"skxq": "",
"skjc": "",
"kkxsh": ""
}
data = urllib.parse.urlencode(data).encode('utf-8')
# for item in cookie:
# print('%s : %s' % (item.name,item.value))
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
}
request = urllib.request.Request(url=urlCheck, headers=headers, data=data)
cj = cookie
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
r = opener.open(request)
response = r.read().decode('utf-8')
if("login" in response):
return 2 #Cookie espire
jsondata = json.loads(response)
totPage = int(jsondata["object"]["totalPages"])
curPage = curPage + 1
for item in jsondata["object"]["resultList"]:
#print(item.get("KXH"))
if(int(item.get("KXH"))==int(kxh)):
find = True
if(int(item.get("kyl"))>0):
if(xuanke(kch,kxh,cookie)):
print("课程\"%s\"选课成功,谢谢使用\nBy Bluefissure"%(item.get("KCM")))
sys.exit()
else:
print("课程\"%s\"课余量不足,您需要等待至少 %s 人退课"%(item.get("KCM"),-int(item.get("kyl"))+1))
break
if(not find):
print("找不到该课程,请确认课程号、课序号!")
sys.exit()
except Exception as e:
print("Check Error: %s"%e)
选课过程老简单了,直接看抓包的数据如下: 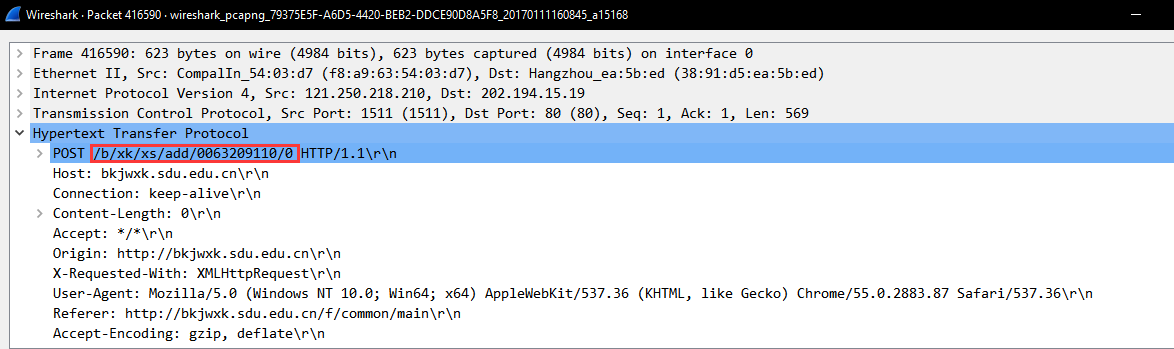 厉害了,直接访问下/b/xk/xs/add/课程号/课序号
就好了,代码太简单都不用贴的……
然后返回的内容还是json,提示信息是utf-8编码(中文),在wireshark里好像显示不正确:
厉害了,直接访问下/b/xk/xs/add/课程号/课序号
就好了,代码太简单都不用贴的……
然后返回的内容还是json,提示信息是utf-8编码(中文),在wireshark里好像显示不正确:
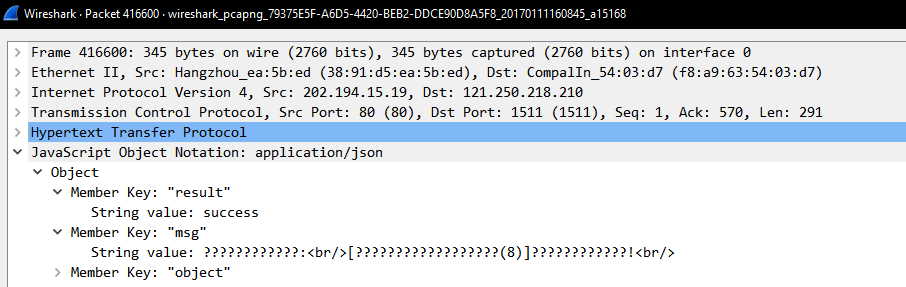 在Python里解码就好了:
在Python里解码就好了: 1
2
3
4
5
6
7
8
9
10
11
12
13def xuanke(kch,kxh,cookie):
try:
urlXuanke='http://bkjwxk.sdu.edu.cn/b/xk/xs/add/%s/%s'%(kch,kxh)
request = urllib.request.Request(url=urlXuanke)
cj = cookie
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
r = opener.open(request)
response = r.read().decode('utf-8')
result = json.loads(response)["msg"]
print(result)
return("选课成功" in result)
except Exception as e:
print("Check Error: %s"%e)
其他问题
- Cookie可能过期,因此每次访问时如果发现有重定向至Login页面的返回时,要重新登录更新cookie
- 其实系统架构大可不必检测课余量,直接暴力强行选就行,反正新系统的接口这么方便……但是,嘛,总感觉暴力去搞有一些DOS的感觉,不要这样搞为好(有人看了这篇博客后去DOS的话那是最骚的)
最后
发现bug的话欢迎来github提吖,测试并没有怎么做。 本脚本仅做学习交流用途,请勿将其大规模用于实践。 作者并未参与一切类似功能的发行版软件的开发,使用本脚本以及同类发行版软件的责任请由使用者自负。
喵喵。